

The fear of missing Microsoft Fabric
We’re sure you’ve all seen the latest Microsoft launch – Fabric.
We want to use this blog to give you a high-level overview of what Fabric is and how it could be used by businesses to meet their data needs.
At it’s core Microsoft Fabric is a comprehensive SaaS platform, it’s a fusion of intelligent cloud computing, advanced analytics and scalable services. Fabric is a solution aimed at democratising data for business and makes analytics easier and more accessible by centralising a wide range of tools. It is a SaaS approach to simplifying end-to-end Data Analytics solutions by unifying data engineering, storage, warehousing and analytics. The aim is to reduce data silos and create more seamlessly integrated data platforms by packaging current Microsoft data products and services into 7 workloads. In essence one unified place to meet all of an organisation’s analytics requirements.
In the past we have been restricted to data tools only suitable for one particular data requirement, however Fabric brings together Azure Data Factory, Azure Synapse Analytics and Power BI. This typically is what is referred to as a specific data workload. If you wanted to do a more strategic piece of advanced analytics on a large dataset, you would’ve had to by manually integrating a different toolset. Fabric essentially allows us to complete these different workloads in one toolset and on a common and shared dataset.
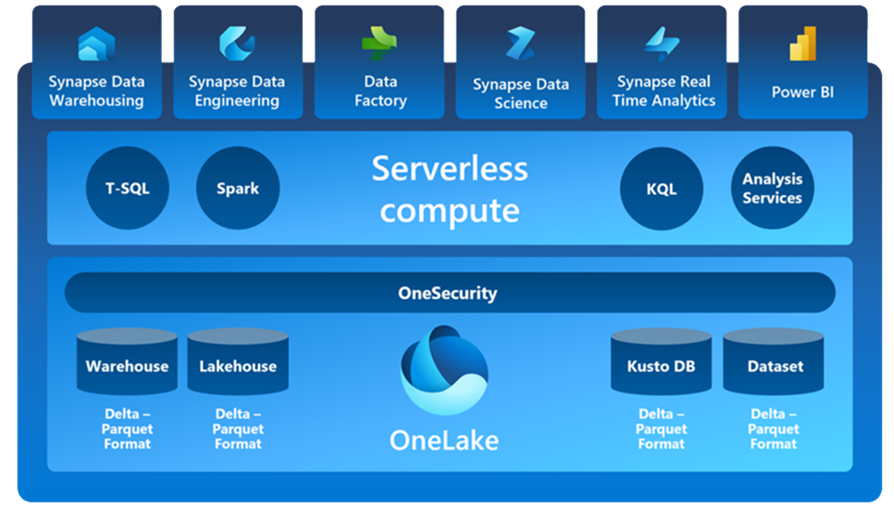
At the centre of Fabric is a data lake or OneLake which underpins these 7 workloads and stores data in a consistent open format, allowing these workloads to easily ingest and integrate with each other. OneLake allows for security and policies to be centrally applied, streamlining the process considerably rather than maintaining it at an individual service level.
The 7 Workloads
The 7 workloads can be viewed as stages of bringing data together and gaining insights:
- Workspace Creation – Instead of provisioning resource the first step now is to create the workspace you would like all of your data assets to sit in, similar to creating a resource group. You also need to make sure you have Fabric enabled in your tenant to create a Fabric workspace.
- Data Ingestion – Within Data Factory there are over 150 connectors to multi-cloud and on-prem data sources which can be easily used to orchestrate data pipelines. Multiple data sources can be combined within dataflows as a simple drag and drop experience.
- Data Transformation & Storage – Data can be stored within the Synapse Data Warehousing workload in an open Delta Lake format which optimises performance by reducing the need to transform and duplicate the data. Fabric favours a lakehouse architecture providing a simple way to store, manage and analyse structured and unstructured data in one place. Synapse Data Engineering offers the capabilities to run Spark notebooks for further data transformation in a code-first approach.
- Analytics & Report Development – Once the data is ready to be consumed it can be used directly as a dataset source for Power BI Reporting to start getting insights from the data. Alternatively, The Lakehouse datasets have auto-generated TDS/SQL endpoints for other reporting tools. Synapse Data Science allows you to also start doing ML on top of the datalake using low-code tools or Notebooks and Visual Studio Code. It is also possible to serve the ML predictions easily to Power BI in real-time using Direct Lake. For scenarios where real-time streaming data is required Synapse Real-Time Analytics helps easily integrate this workload into the Fabric assets and democratise the data. It can handle structured or unstructured data while flexibly scaling out to meet unlimited amounts of data and importantly indexing and partitioning the data to keep the focus on advanced analytical solutions.
The diagram below shows the workloads in Fabric which are underpinned by OneSecurity and one storage approach with the OneLake
Direct Lake
A key feature release in Fabric is Direct Lake for Power BI which promises the performance of import mode but offers real-time data. Queries are sent straight to the lake and loads data straight into Power BI, so there is no importing of data and no need for query translation due to the Delta parquet columnar format in which the data is stored. This reduces a commonly tricky task of moving data to Power BI and maintaining refresh schedules again breaking down another data silo.
Git PBI
The release of Git integration with Power BI has been slightly overshadowed by Direct Lake but is just as interesting as now it unlocks the capabilities for much easier version testing and the collaboration of Power BI files. The ability to save Power BI files as projects means the dataset and report are saved in separate folders and so can better integrate into testing and validation pipelines. Workspaces within Fabric can directly integrate with git branches allowing for backups to be saved and roll backs when needed. Currently Fabric workspaces only support Devops integrations with Power BI workloads but more items are said to be available in the future.
Tenants
Fabric follows a capacity licensing model based on F SKUs which can be turned on/off at any time furthering the idea of an easily scalable platform. Yearly licencing contracts are not currently available but are on the roadmap.
What’s next?
Fabric has great potential in changing the data landscape, but we are only at the beginning. We’re excited about what else there is to come, and we want to share as much as we can with you, so look out for more blogs and resources around Microsoft Fabric.


- Share
